


Superior Accuracy & Reliability of Translation Versus Industry-Grade Machine Translators
January 23, 2025

In the dynamic and sensitive world of healthcare, accuracy in communication is critically imperative to providing safe, equitable and exceptional quality of patient care. Miscommunication between clinicians and patients, particularly those who speak different languages, can lead to critical misdiagnoses, delays in treatment and compromised patient safety, that may be the difference between life or death in certain cases. As the field of technology rapidly evolves, so too do novel opportunities that foster enhanced quality and accessibility of communication between Limited-English Speaking Patients (LEP) and their care teams. Aavaaz is deeply dedicated to solving this devastating unmet need with the next generation of state-of-the-art multilingual, multimodal translation technologies. To ensure our technology meets the highest standards of reliability and precision, we have benchmarked our model performance against industry-grade machine translators and conducted rigorous evaluations tailored to the unique and vast demands of clinical care settings. This report provides a detailed analysis of our superior accuracy metrics and highlights their critical relevance to ensuring reliable, safe, and precise machine translation in healthcare.
To deeply ensure the robust accuracy of Aavaaz’s neural machine translation models, we utilized a comprehensive set of both industry-standard metrics and internal Aavaaz validation techniques.
After multiple iterations of model training, human feedback, iteration and retraining were completed demonstrating strong consistency of acceptable outputs, the final model metrics were conducted as below using BLEU and METEOR scores.
To capture a broad range of real-world situations and ensure generalizability of results, phase 1 testing language was analyzed on a set of 6 common clinical conversation types across 10 specialties as listed below:
Conversation Types:
Medical Specialties:
The base dataset was compiled through human translated text, including a variety of inputs from medical interpreters, multilingual clinicians, linguists, and community members to avoid any potential bias from singular translations by one individual. The robust testing dataset includes bidirectional patient and doctor conversations across six conversation types and spanned ten medical specialties (as listed above). These initial conversation and specialty categories were chosen based on the highest relevance of clinical scenarios – further expansion will continue to represent broader context across healthcare experiences. The base dataset will also be released for public view in upcoming publications.
This analysis evaluated the superior performance of Aavaaz, a neural machine translation model, as compared to Google Translate and GPT across multiple languages, utilizing BLEU and METEOR scores to assess translation quality, accuracy and reliability. BLEU and METEOR were selected considering wide standard usage in assessing the quality of machine-generated translations by comparing them to human references. The plots included below provide graphical illustrations to visualize average scores for each system, highlighting relative performance across different languages. This analysis is relevant for understanding the strengths and weaknesses of these systems in multilingual translation tasks, particularly in the context of sensitive clinical conversations between patients and care teams.
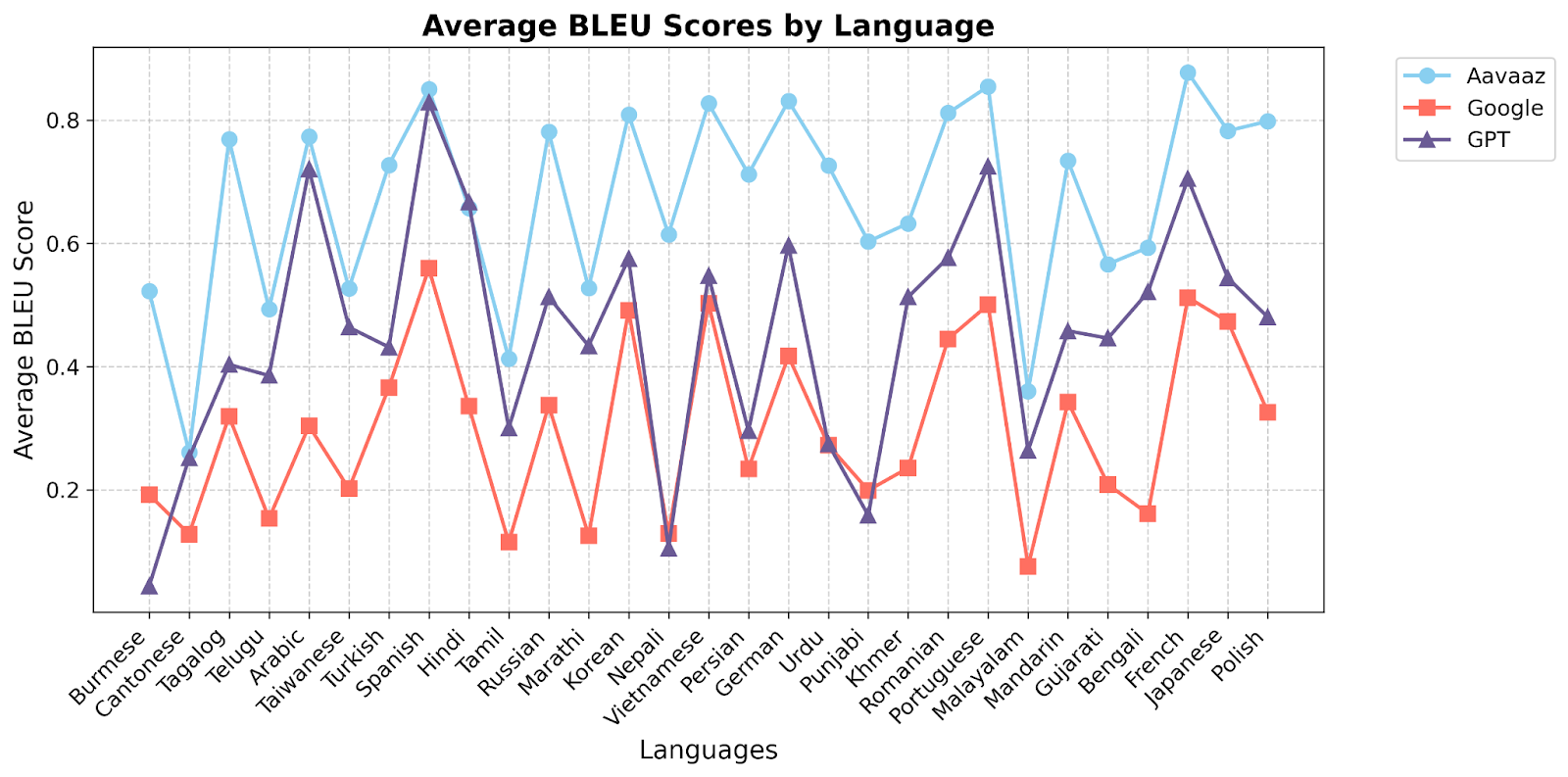
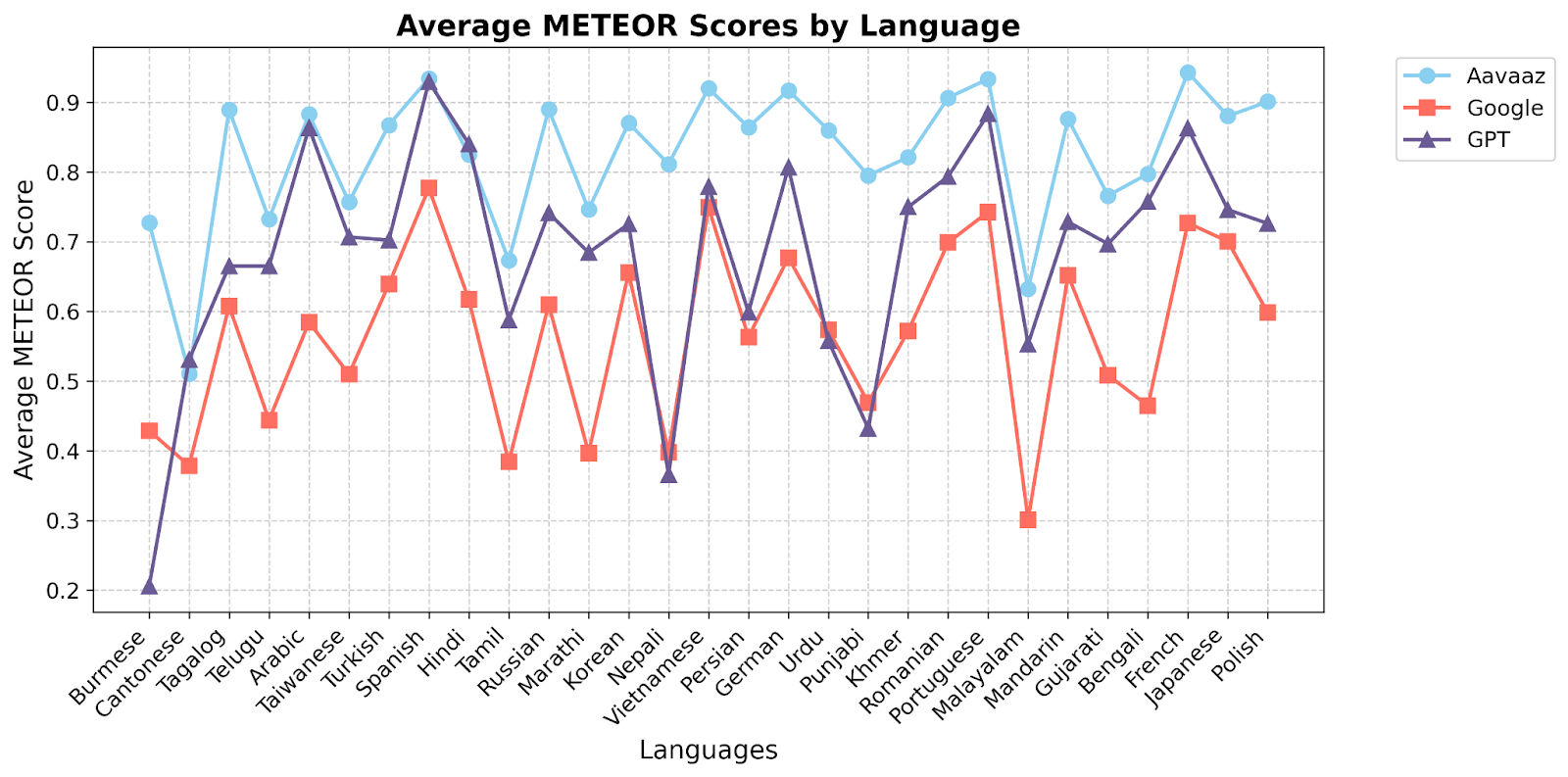
The evaluation of BLEU and METEOR scores across multiple languages highlights Aavaaz's exceptional performance, consistently surpassing Google and GPT models in most cases with significantly higher average scores. These results reflect Aavaaz's unparalleled superiority against leading incumbent technologies to not only accurately translate at baseline, but to also handle complex linguistic structures and cultural scenarios that to deliver precise, contextually accurate translations, positioning it as the gold standard for healthcare-related colloquial translations. The superior accuracy and precision of Aavaaz emphasizes its critical role in ensuring reliable and clear communication across a broad range of clinical settings, where even minor errors can have serious implications. This report not only showcases Aavaaz’s leadership, strength and reliability in multilingual translation technologies but also reinforces its future potential to redefine industry standards, ensuring safe, robust, and dependable solutions that redefine health equity across the global borders.
