


Empowering Clinicians and Patients to be an Active and Essential Voice Throughout Technical Development
January 23, 2025

The integration of artificial intelligence into healthcare has sparked ongoing debates about the appropriate and safe role of humans versus technology in delivering care. However, framing this as a binary choice oversimplifies the reality and scope. The most effective AI solutions are not those that replace humans but those that amplify human expertise and expand human capability. To achieve this level of technological development at a safe and acceptable level of excellence, clinicians and patients must be active participants in shaping the development of healthcare technologies to ensure that these tools meet real-world needs. Their insights and lived experiences are invaluable in designing systems that are accurate, empathetic, and contextually relevant. In developing our technology, we strongly prioritized embedding the voices of clinicians and patients throughout the development, testing and validation process. If innovation is to be built for patients and healthcare teams, it must be built by patients and healthcare teams as well. This paper outlines the steps taken to evaluate the technology's performance, including the integration of human expertise in an iterative feedback cycle, detailed error categorization, and longitudinal validation to ensure its sustained utility in real-world settings. It aims to demonstrate the robustness and depth of our testing methodology, showcasing how our human-in-the-loop evaluation framework ensured the highest standards of accuracy, precision, and contextual relevance before deeming fit for a clinical setting.
To deeply ensure the robust accuracy of Aavaaz’s neural machine translation models, we utilized a comprehensive set of both industry-standard metrics and internal Aavaaz validation techniques.
The primary objective of this evaluation was to validate the system's accuracy, safety, and usability for multilingual clinical communication in real-world medical settings. Specifically, the evaluation aimed to:
Development and Pre-Evaluation Preparation
The system was tested using a diverse dataset of medical and colloquial expressions sourced from public and proprietary domain-specific corpora.
Quantitative Evaluation
Quantitative evaluation was conducted using established NLP metrics such as BLEU, METEOR. These metrics were applied to assess translation accuracy, fluency, and contextual alignment. Special attention was given to medical terminology, colloquial patient expressions, and high-stakes clinical instructions. Statistical analyses were performed to identify patterns of error and variation in performance across different languages and specialties.
Human-in-the-Loop Feedback
A human-in-the-loop feedback cycle was central to the evaluation process. Medical professionals, linguists, and bilingual experts reviewed the system's output in real-time, focusing on translation errors, contextual misinterpretations, and tone inconsistencies. Annotated feedback was used to iteratively refine the system, ensuring that it met the nuanced requirements of clinical communication.
Scenario-Based Testing
The system was tested across a range of clinical scenarios, including emergency triage, chronic disease management, and mental health counseling. Evaluators assessed its ability to handle conversational complexity, such as switching between colloquial and technical language or interpreting idiomatic expressions. These scenarios were drawn from specialties like cardiology, oncology, pediatrics, and psychiatry to ensure broad applicability.
Error Analysis and Risk Mitigation
Errors identified during evaluations were categorized into an error taxonomy that included mistranslations, contextual inaccuracies, and inappropriate tone. High-risk errors, particularly those involving medication dosages or surgical instructions, were flagged for immediate resolution. Mitigation strategies included retraining the model with augmented datasets and refining attention mechanisms to better capture context.
Longitudinal Validation
To evaluate sustained performance, the system was deployed in pilot healthcare settings for six months. Feedback from healthcare providers and patients was collected to monitor its reliability, adaptability, and impact on communication outcomes over time.
The evaluation demonstrated that the system achieved high levels of accuracy and contextual
relevance. Quantitative assessments showed significant improvements in BLEU and METEOR
scores after iterative refinements, with a substantial reduction in critical errors compared to
initial benchmarks. Scenario-based testing confirmed the system's ability to handle diverse
medical conversations effectively, with the majority of evaluators reporting high confidence in
the translations' safety and accuracy.
Human feedback was instrumental in identifying and addressing context-specific errors, such as
those related to regional dialects or idiomatic expressions. Longitudinal validation further
established the system's reliability in real-world clinical settings, with feedback indicating
enhanced communication efficiency and patient satisfaction.
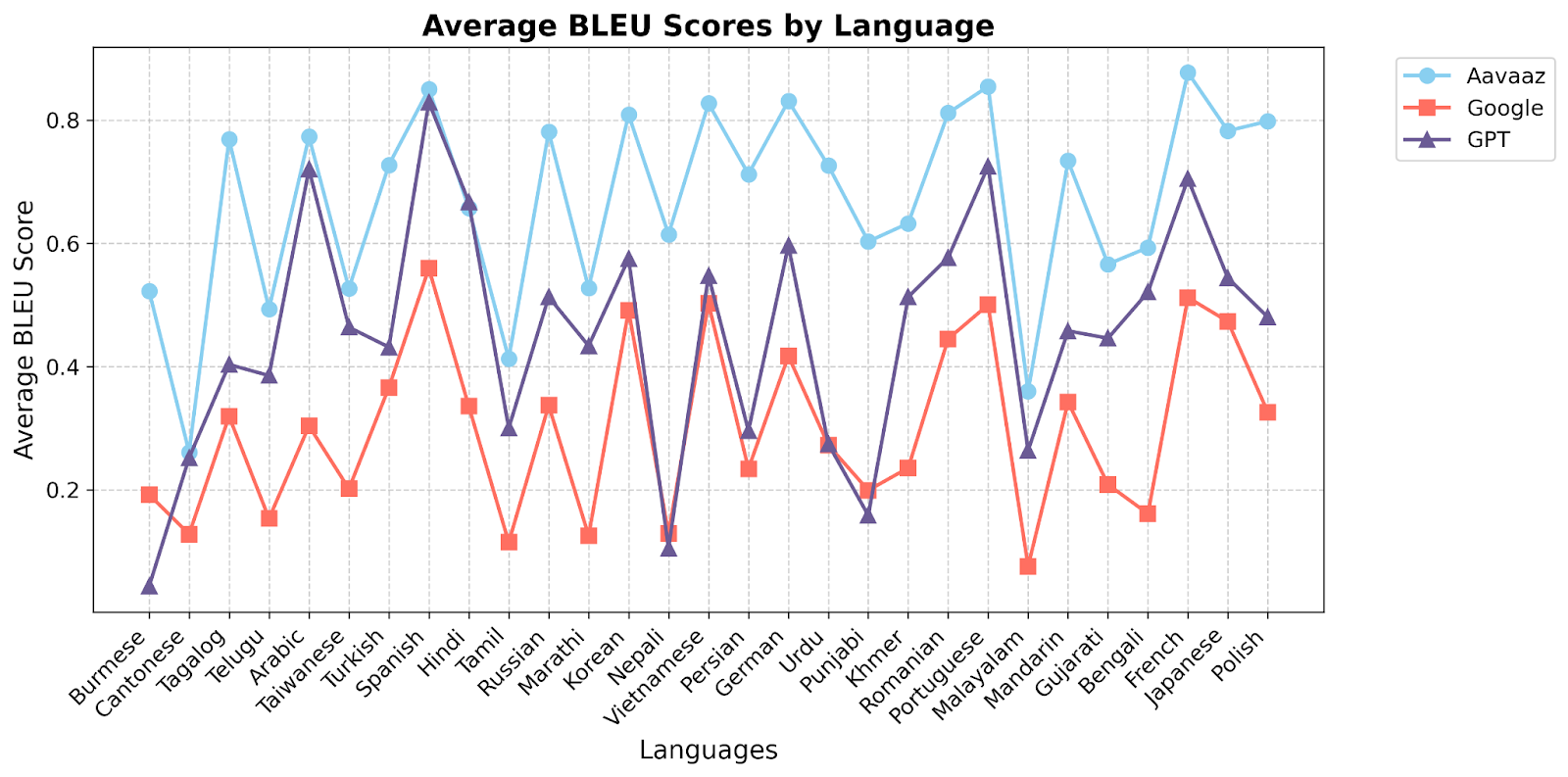
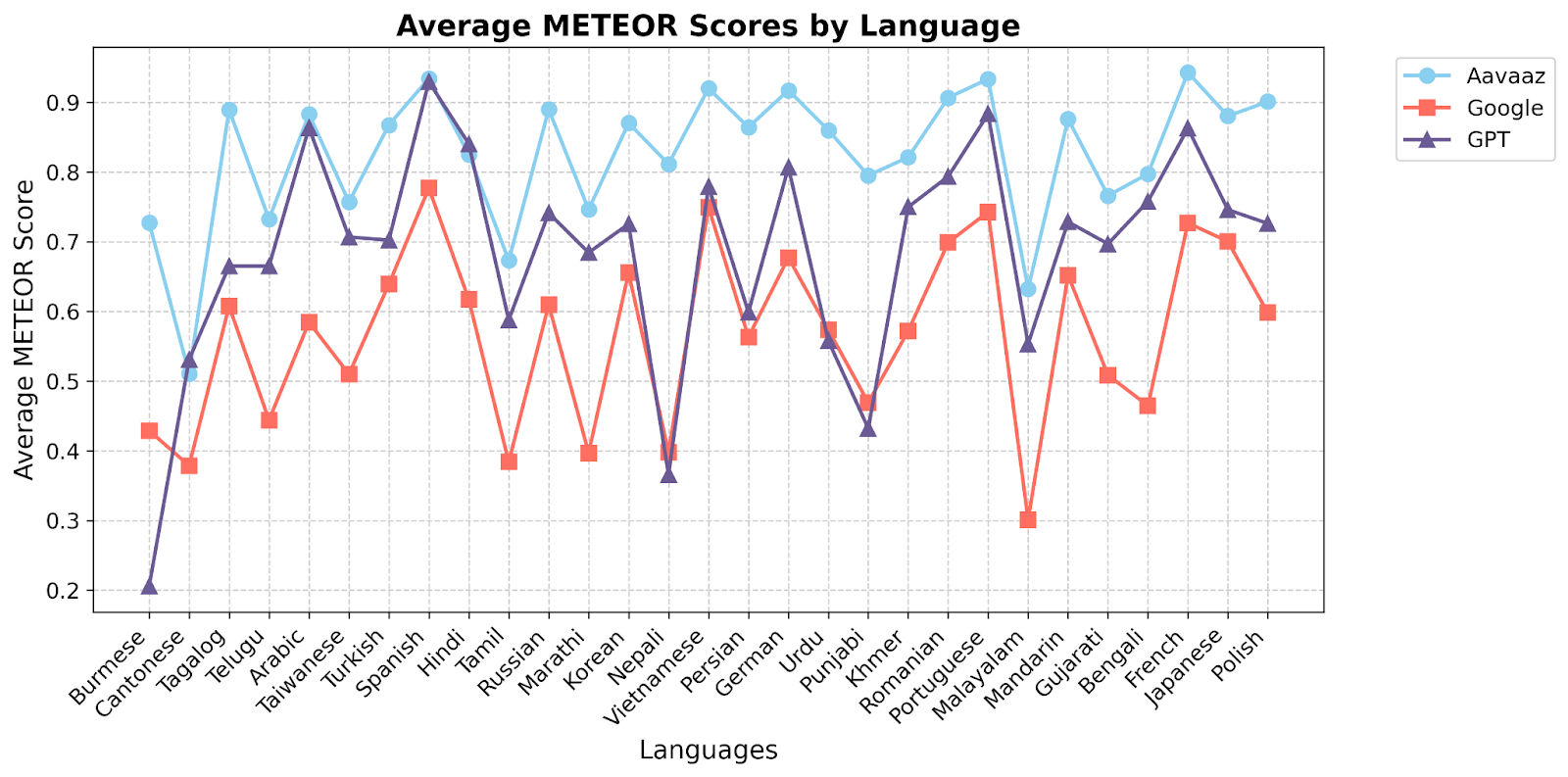
The layered evaluation framework highlighted the importance of combining quantitative metrics with qualitative human assessments to ensure the system's reliability and safety. The iterative feedback process allowed for continuous improvement, addressing the dynamic and nuanced needs of clinical communication. While the results are promising, ongoing refinements will focus on expanding the system's capabilities to additional languages, dialects, and medical specialties.
This evaluation underscores the critical role of robust testing in developing AI technologies for healthcare. By prioritizing accuracy, contextual relevance, and ethical considerations, our multilingual speech-to-speech translation system offers a reliable solution to bridging language barriers in clinical settings. Future work will continue to enhance the system's adaptability and ensure its alignment with the evolving needs of global healthcare.
